MedicaLLM Evaluation
Rigorous evaluation framework for multilingual medical AI systems in maternal healthcare contexts

About LLM Evaluation
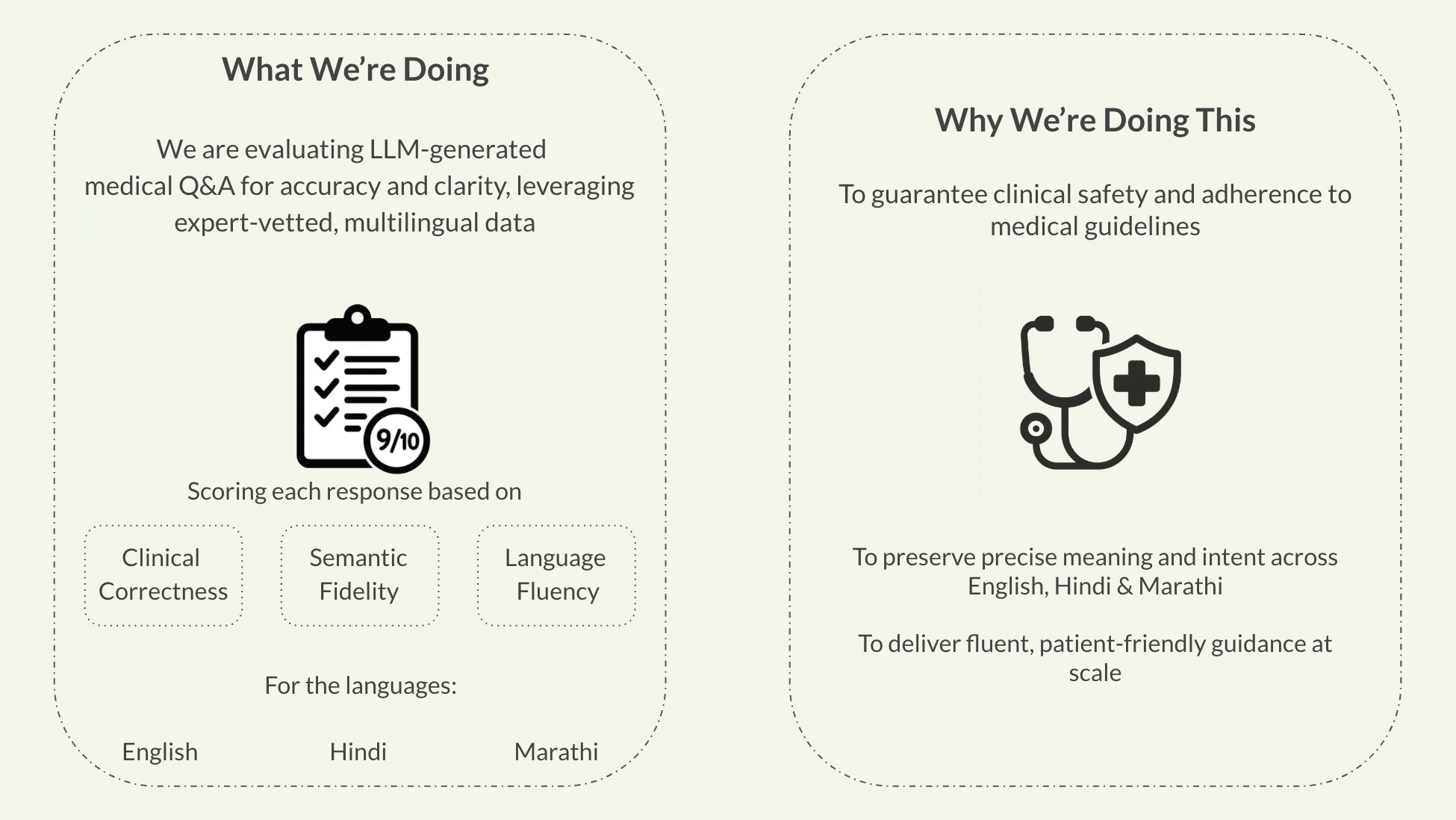
Medical LLM Evaluation establishes systematic protocols for validating AI-powered language models in maternal healthcare applications. Our framework evaluates Large Language Model performance across English, Hindi, and Marathi using expert-validated question sets, weighted scoring mechanisms, and multi-dimensional assessment criteria. This infrastructure enables evidence-based validation of AI systems prior to deployment with patients and community health workers in resource-limited settings.
Our Solution
Comprehensive AI model testing and validation protocols.
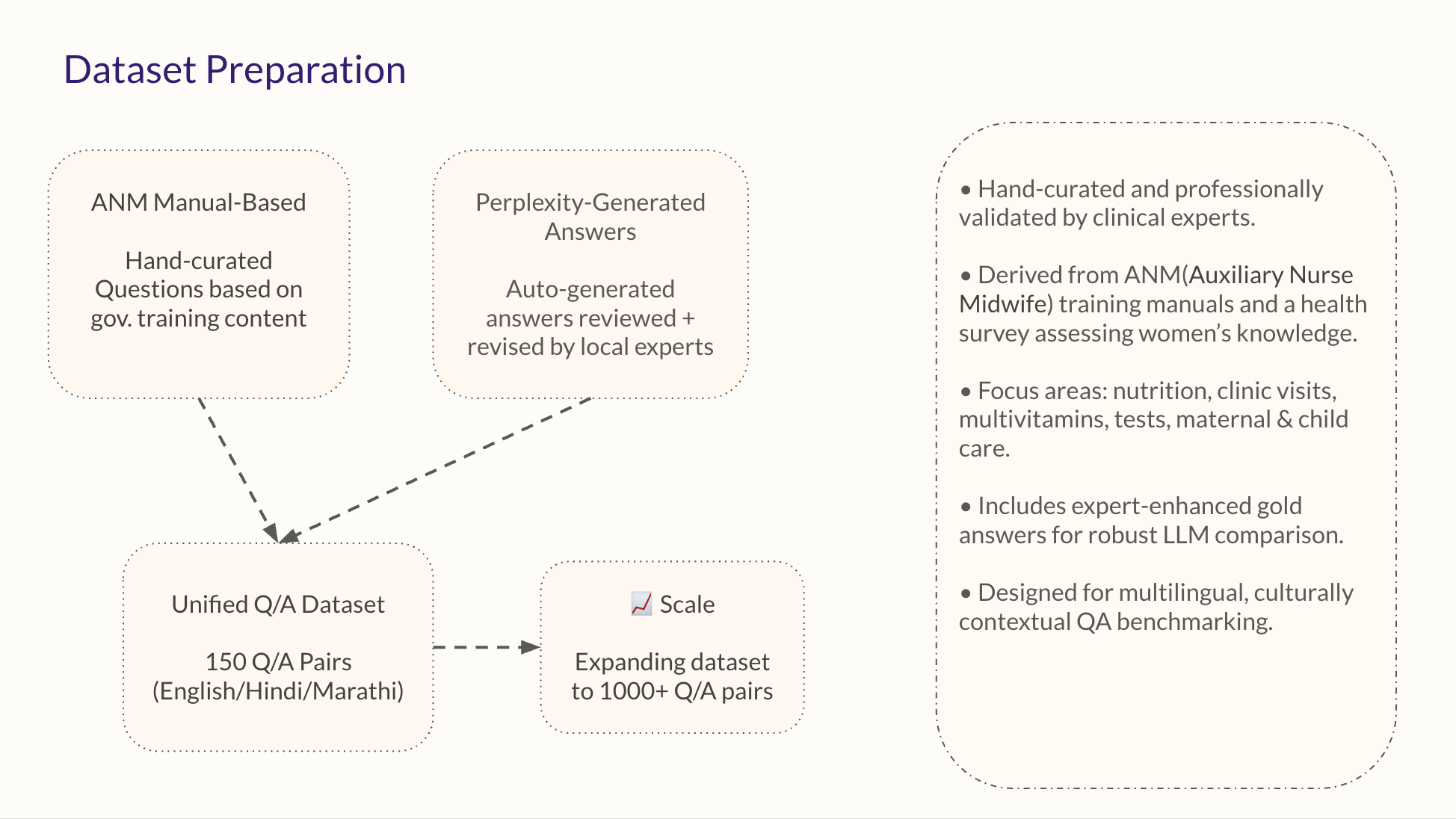
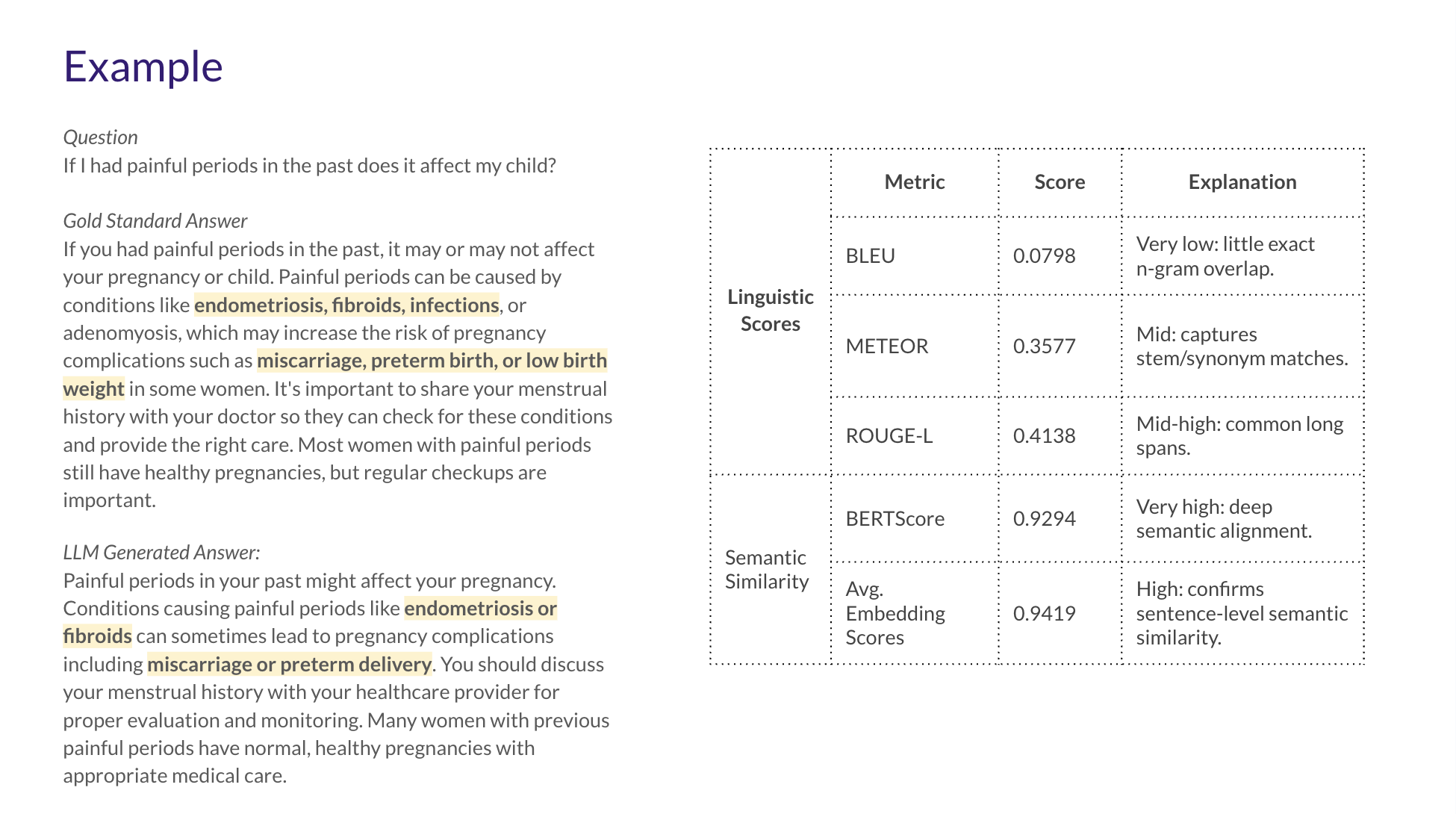
A gold-standard dataset of questions and answers created and validated by local medical experts.
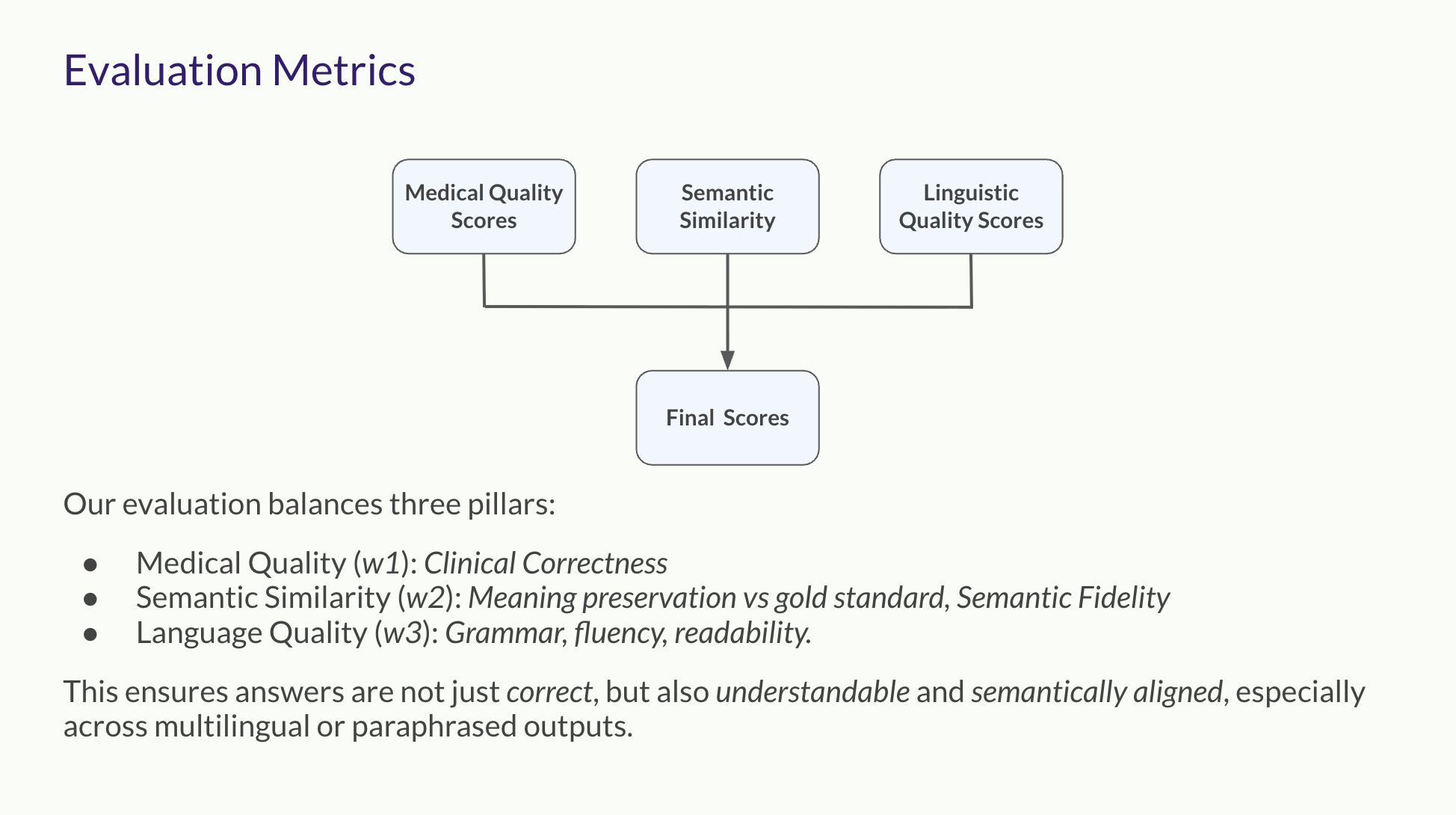
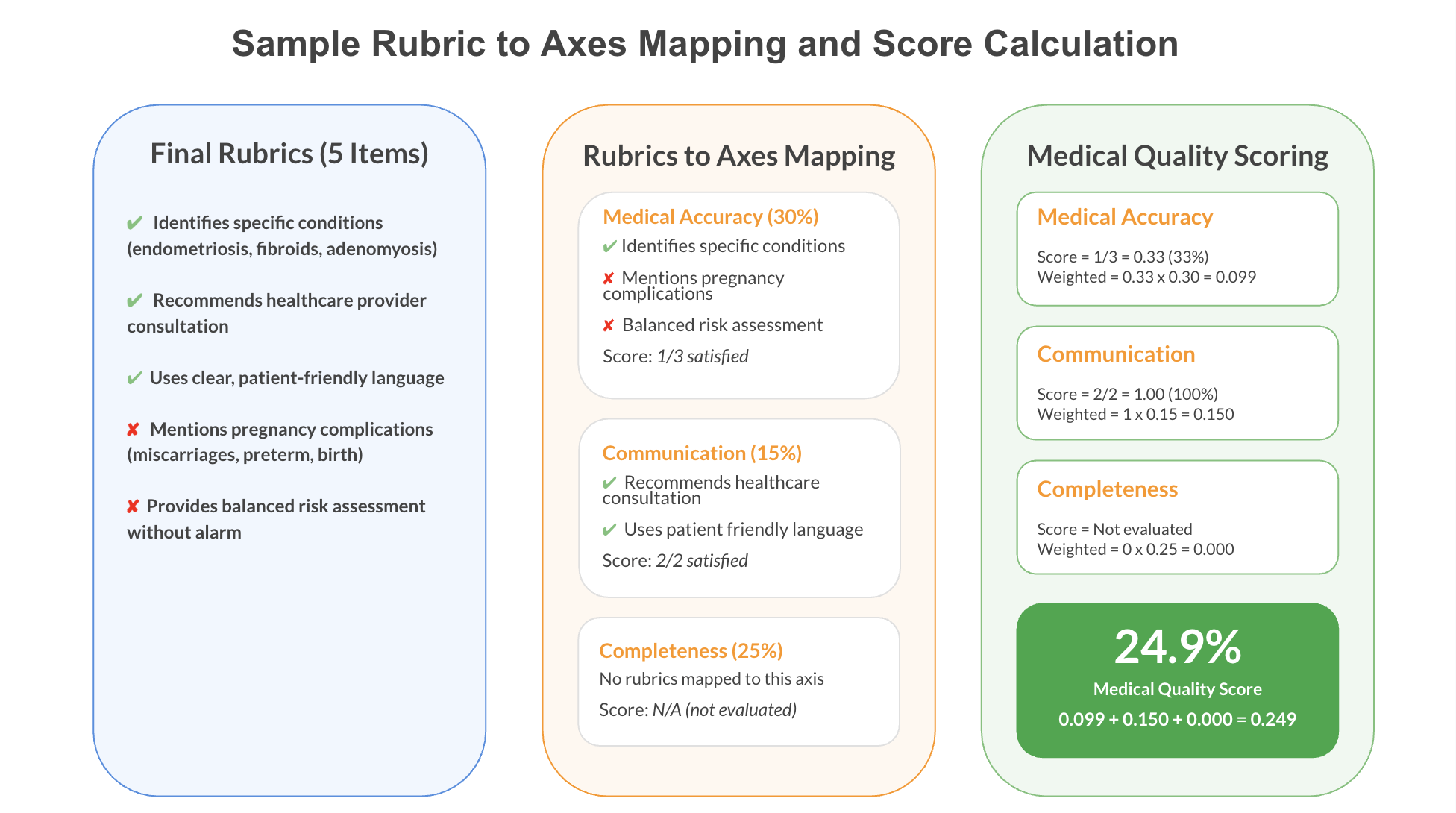
A professionally weighted scoring system to determine the clinical accuracy, completeness, and contextual safety.
Evaluation of responses on multiple dimensions: medical quality, semantic similarity, and language quality.
Focus on low-resource languages like Hindi and Marathi to ensure linguistic accessibility and cultural relevance.
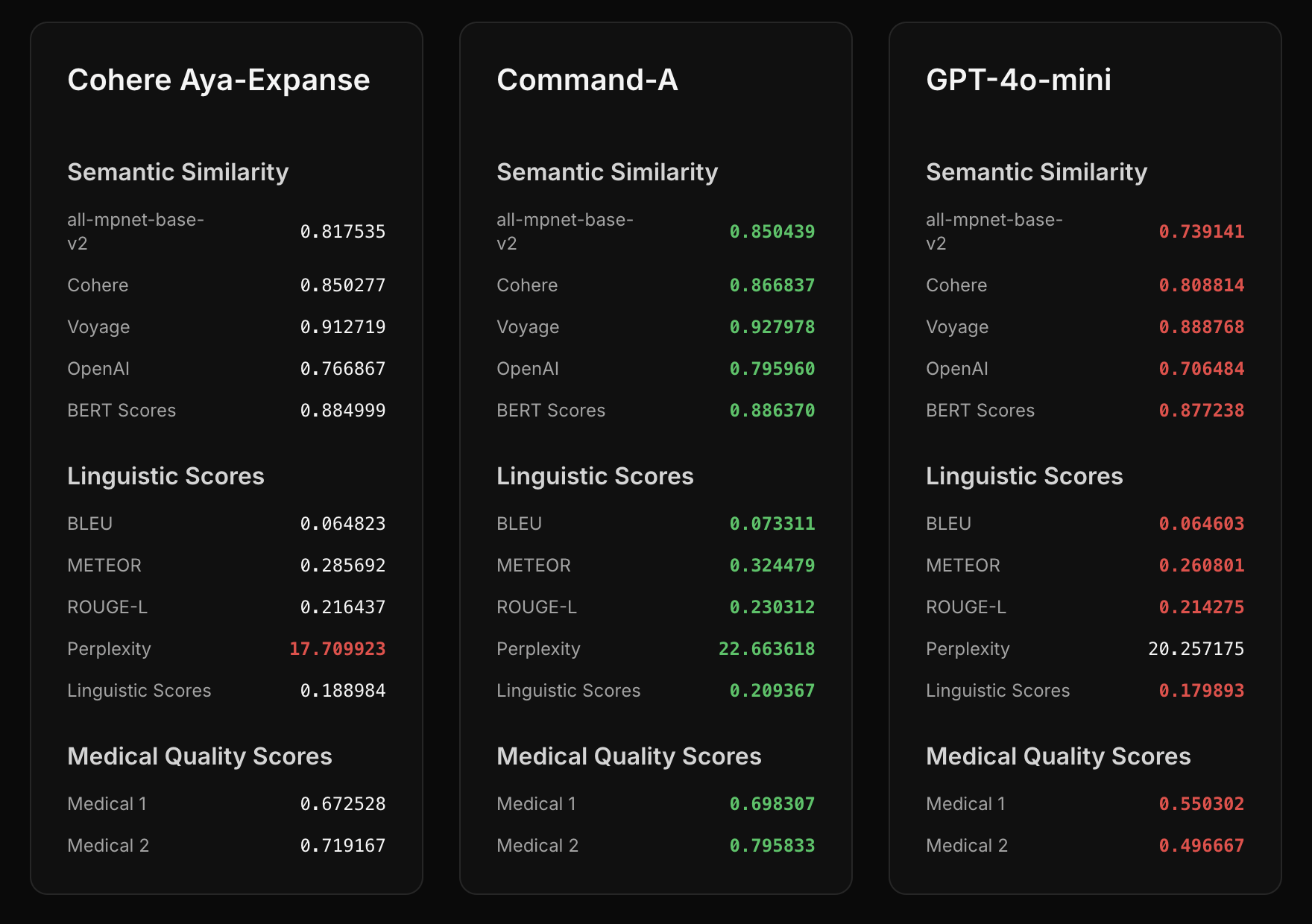
Utilization of state-of-the-art NLP models like Cohere's Command-A and Aya Expanse for multilingual QA.
A holistic final score that aggregates medical, semantic, and linguistic quality for a complete performance metric.
Why LLM Evaluation Stands Out
Unique Value
- Comprehensive multi-dimensional evaluation framework
- Real-time bias detection and mitigation tools
- Regulatory compliance and safety assessment
- Clinical validation with healthcare partners
Evidence of Success
*Including Cohere's Command-A and Aya
English, Hindi, Marathi
*Semantic Similarity, Linguistic Analysis, and LLM-based Evaluation.
Medical LLM Evaluation Platform Showcase
These slides demonstrate our comprehensive approach to assessing medical AI systems, featuring our dashboard interface, scoring mechanisms, and validation methodologies.


Meet the Team

Varun Nair
Machine Learning Engineer
D.J. Sanghvi College of Engg.
B. Tech Computer Engineering ‘ 25

Himanshu Beniwal
Mentor
PHD Student
Indian Institute of Technology Gandhinagar

Dhara Mungra
CTO
Data Scientist
MS, New York University

Swapneel Mehta
Chief Scientist
Postdoc, MIT & Boston University
Ph.D. New York University